How We Use Elasticsearch for Hiveage

Hiveage, our flagship SaaS product, is used to manage the business finances of thousands of customers from more than 140 countries. Imagine for a moment the number of statements—invoices, bills, estimates—and other items that are being created on this platform on a daily basis: without a robust search feature, our customers would find it very difficult to sort and filter their financial data.
In this article, we share details on how we improved Hiveage’s search features to be faster, more efficient and more powerful using Elasticsearch.
Previous Setup
From Hiveage’s inception, we were using PostgreSQL’s built-in full-text search capability to power all the text search activities in the application. It’s simple to set up and easy to manage, mainly because the indexing process is tightly coupled with the database itself. No separate service or storage unit is required to handle the indexing.
It uses a separate column in the table itself to store the indexed data, and the indexing is done through stored procedures. Since everything is handled by the database itself, indexed data will always be synchronised with the database data, which makes it a very convenient option.
Why Elasticsearch?
Although its full-text search is certainly a great feature, PostgreSQL is still a relational database. With regard to full-text search, our requirements continued to grow beyond what Postgres could deliver, so we considered several full-text engines and settled on Elasticsearch.
Elasticsearch is a dedicated full-text search service based on the Apache Lucene search engine. Apart from the well-known performance perks and a huge set of new features, below are some of the reasons why we made the move to Elasticsearch.
Higher Flexibility
Elasticsearch’s powerful API provided exactly what we needed: the ability to manage flexible and complex search queries. It has its own JSON-based Domain Specific Language (DSL) to perform queries supporting many features. Additionally, Ruby has a rich set of libraries and a strong community supporting Elasticsearch.
Index complex data structures with many associated attributes
Indexing and searching through associated objects are poorly supported in PostgreSQL’s built-in full-text search. But in Elasticsearch, there are several convenient ways to handle relationships between objects.
Scalability
Elasticsearch is distributed by nature and also supports multi-tenancy, so it’s highly scalable compared to PostgreSQL.
Reduce the Load on the Database
When the database itself manages text indexing, it puts additional load on the database. This affects the performance of regular database operations. Moreover, using the main database for two purposes makes it inconvenient when we want to re-index a text column or similar text-related operation.
New setup
Indexing
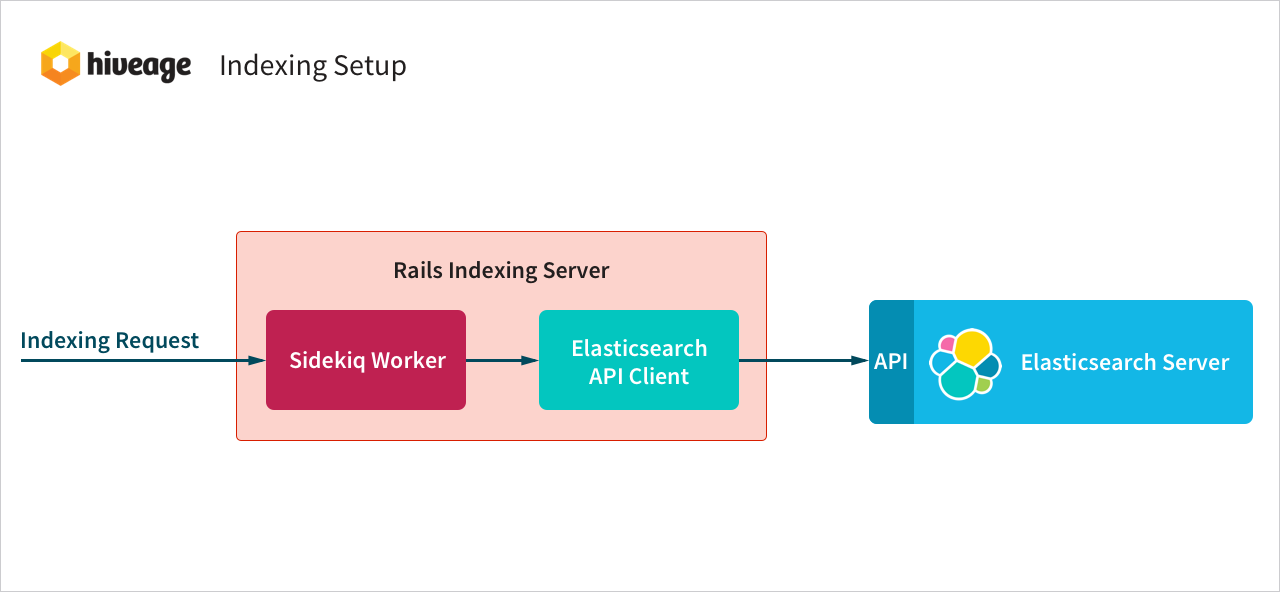
- When a database record gets created, updated or deleted, Rails’ “after_commit” callback will fire.
- A new Sidekiq indexing job will be created and get queued in the Redis store.
- One of the Sidekiq workers running on the Rails indexing server will pick up the job from the Redis store and execute it.
- Finally, an indexing request will be sent to the Elasticsearch server using the Elasticsearch API.
Background Processing
Indexing is best done asynchronously, ideally using a background process. This reduces the load on the Rails server instance. We use Sidekiq as the background processing service. Multiple Sidekiq workers are used concurrently to increase indexing efficiency.
Isolated Rails Environment for Indexing
To reduce the load on the Hiveage application server, we are using replicas of the Hiveage app in a private subnet dedicated to handling indexing operations via Sidekiq workers. This provides independent working environments for both the Hiveage application and indexing processes and also provides the autonomy to horizontally scale on demand.
Solving Different Challenges
1) Multiple Sidekiq workers are being used concurrently for indexing operations, but this comes with its own set of difficulties. When a record (which associates with many other objects) is updated, a batch update needs to be carried out to index all its associated objects, which is a resource-intensive operation. We call such an operation an “associative batch update.”
E.g.: When the connection object is updated, all of its associated records (i.e., invoices, bills, estimates, etc.) have to be indexed again.
An associative batch update can take from seconds up to a few minutes to process all associated records. During the batch, a newer update for the same record can cause another batch indexing operation and introduce a race-condition-like situation.
In order to maintain the mutual exclusion between index operations of the same record, we use distributed locking using Redis to lock the record while the batch is being processed. None of the other Sidekiq workers can index the same record while one Sidekiq worker is already locked onto it. The lock is released once the indexing process is finished.
2) Sidekiq’s built-in retry mechanism re-attempts failed jobs for some defined number of times. But this mechanism can re-attempt an older request after a successful recent update in which case the old (failed) request will overwrite the recent update. Also, in rare cases, network asynchronicity can cause index requests to be queued out of order.
We maintain a timestamp of the last indexed time of each record in a Redis store. Every time a new index request is created, the timestamp of the resource change (create/update/delete) is added to the request. When a new index request is received at a Sidekiq worker, it compares the last indexed timestamp of the record (from the Redis store) with the timestamp of the index request. If it’s old, it simply rejects the request.
3) A current executing associative batch update can become stale because of a newer update to the same resource. Running a stale associative batch update is a waste of resources.
To mitigate this, we again use the timestamp to determine whether there is a newer batch update. If there is one, the current batch operation will be terminated allowing the newer batch update to take its place.
Indexes and Types
The first step of implementing Elasticsearch was to create indexes and types. A single index can contain multiple types. In relational database terminology, types are similar to tables, where records belonging to a similar data structure (field mappings) can be stored.
From a bird’s-eye view, there are two approaches to designing an Elasticsearch store:
- Create multiple indexes having one type per index by mapping each domain-wise entity (usually a database table) to the type in the index.
- Create multiple types per index by mapping multiple relational database tables to the types inside a single index.
Both approaches have their own pros and cons. We chose the second approach due to the following reasons:
- Most of our resource types (invoices, bills, estimates, etc.) contain similar field mappings (limited sparsity); hence, it’s ideal to map different resource types to different types under one index.
- The number of searchable resource types (invoices, bills, connections, items, expenses, tags, etc.) in Hiveage is quite high. So keeping a separate index for each resource type adds a fair amount of overhead to the nodes, which leads to adding more nodes to the system. But since our data is still on a scale of millions, shards in each index will be underutilized and would be a waste of resources. So maintaining multiple types under a single index works best for the time being.
- It’s usually easier to deal with one index rather than maintaining a dozen of them.
Mapping
The next step was to create Elasticsearch mappings. Mappings are used to map fields of classes or regular database tables into fields of Elasticsearch documents. Each field should have a data type which could be an integer, float, string, Boolean, date, etc. Optionally, we can also specify an analyzer to be used per field; otherwise, the default analyzer will be used.
E.g.:
mappings do
indexes :statement_no, type: 'string', analyzer: "custom_analyzer"
end
One quirk is that if you analyze a certain field, you cannot perform sorting using that field. In order to overcome that issue, another field called a “raw field” has to be added with no analyzer.
E.g.:
mappings do
indexes :statement_no, type: 'string', analyzer: "custom_analyzer",
fields: {
raw: { type: "string", index: :not_analyzed }
}
end
Handling Associated Objects
One of the main reasons to move to Elasticsearch was to add the ability to search through associated objects of an object. There are two popular ways to handle this in Elasticsearch.
| Nested Object | Parent-Child |
|---|---|
| Nested objects are saved in the same document. | Parent and child objects are saved separately in different documents. |
| A child object can have multiple parent objects. | A child object cannot have multiple parent objects. |
| Querying is relatively fast. | Querying is slow because child and parent are stored separately. |
| Can easily maintain multiple nested levels. | Hard to maintain multiple nested levels. |
| Nested level querying is well-defined and simple to use for any number of nested objects. Also Query string can be used to query the nested objects. | Querying gets complicated when multiple parent-child relationships are present. |
| Can retrieve all the data since they are residing in the same object. | Cannot retrieve both child and parent documents in a single query. |
| Nested object gets duplicated for each parent object. | No data duplication involved since the relationship is normalized. |
| If a nested object gets changed, all of the parent objects have to be re-indexed. | No need to re-index the parent because only a connection is maintained between them. |
We decided to use nested objects to handle the associations due to the following reasons:
- Hiveage database models contain multiple nested associations in multiple levels. Therefore, they can be handled easily with the nested object approach.
- In the parent-child approach, a child object cannot have multiple parent objects.
- Nested queries are easier to perform in the nested object approach.
- Unable to retrieve both children and parent fields in a single query.
E.g.:
mappings do
indexes :connection, type: nested, include_in_parent: true do
fields: {
indexes :name, type: 'string'
indexes :email, type: 'string'
indexes :primary_contact_name, type: 'string'
}
end
Analyzers
Elasticsearch provides a highly customizable indexing interface where we can create our own text analyzers by combining character filters, tokenizers and token filters. Analyzers are used to analyze a given text and generate an index of terms according to a given set of rules.
E.g.:
Text : "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
Terms: [ "the", "2", "quick", "brown", "foxes, "jumped", "over", "the", "lazy", "dog's", "bone" ]
This was done using the Elasticsearch’s default analyzer, “standard analyzer.” But we had to use a custom analyzer because the built-in analyzers didn’t generate the terms the way we expected.
E.g.:
Text: "IN-0001"
Standard analyzer output : ["in, "0001"]
Whitespace analyzer output : ["in-0001"]
Expected output : ["in", "in-0001", "0001"]
Custom analyzers which were used:
analysis: {
filter: {
special_character_spliter: {
type: "word_delimiter",
preserve_original: "true"
}
},
analyzer: {
default: {
type: "custom",
tokenizer: "whitespace",
filter: [
"special_character_spliter",
"lowercase"
]
},
default_search: {
type: "custom",
tokenizer: "whitespace",
filter: [
"lowercase"
]
}
}
}
The “special_character_spliter” filter was used to split the text while preserving the delimiter character. The “default” analyzer is used in the indexing stage while “default_search” is used when querying the Elasticsearch server.
Bulk Indexing
Hiveage has millions of records of invoices, bills, connections and other items. These records initially had to be indexed with the Elasticsearch server. However, sending a single index request per each record was not practical given the amount of data. Therefore, we used Elasticsearch’s bulk API, which allows for the indexing of thousands of records in a single request. We used Rails’s find_in_batches method to retrieve and divide the record set into multiple chunks and then indexed each chunk using the bulk API.
Querying
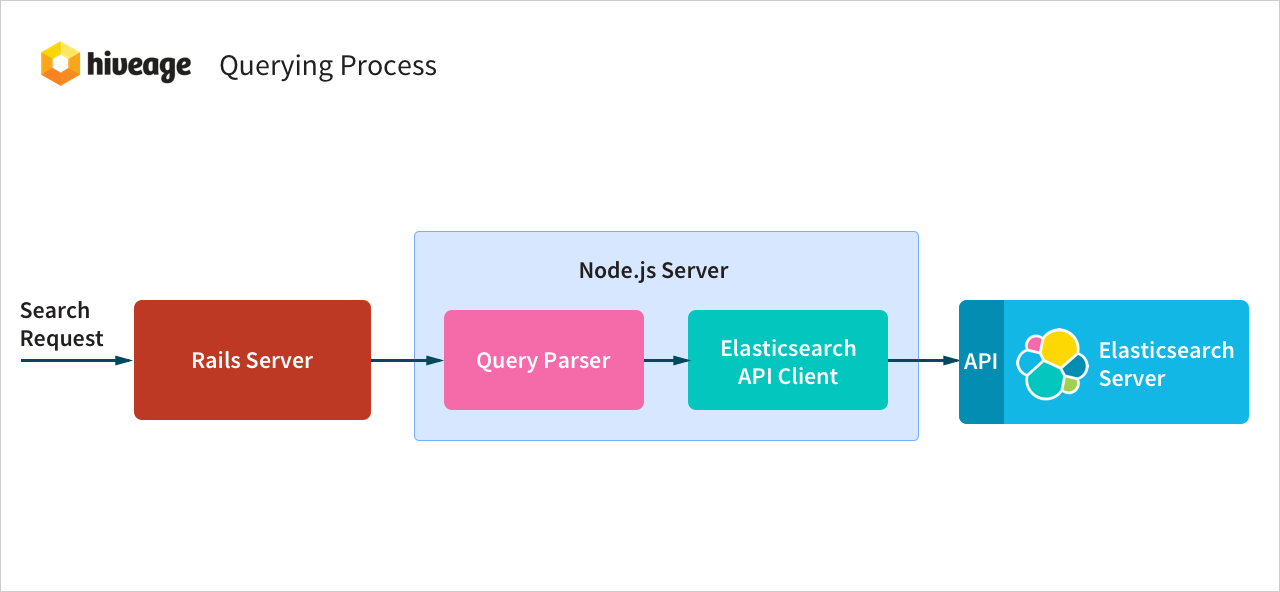
- Search query reaches the Rails server via an ajax request. Additional data such as user timezone, user permissions and filters are added to the search query.
- Search query is then passed to the Node.js server.
- Search query then goes through the custom query parser.
- Output of the query parser is converted to Elasticsearch’s Query DSL format and then sent to the Elasticsearch server via its API.
- Search results are then passed back all the way to the ajax callback.
Why Add a Node.js Server
We added a Node.js server as a middleman between the Rails server and the Elasticsearch server. Its job was to handle the custom query parsing and querying of the Elasticsearch server. The reasons for adding the Node.js client are:
- Directly handle the search request without any intervention from the main application. With this microservice, search query requests will be sent to the Node.js service from the front end itself. This would substantially reduce the search latency and also reduce the application server’s load. This performance update is queued for the next release.
- The microservice approach makes it easier to manage both services: any search-related updates or bug fixes to the custom query parser can be released without re-deploying the application server.
Query Parser
A custom query parser was created in order to simplify the query format used by the Elasticsearch API, particularly when specifying a date, time and amount ranges. It also gives the ability to support multiple date-time formats, making the search query user-friendly.
E.g.:
- date.on:x
- date.after:x
- date.before:x
x = 2016, 2016-01, 2016-01-01, today, yesterday, this_week, last_week, this_month, last_month, january, last_january, sunday, last_sunday etc
- amount.less: 100
- amount:more:100
Our support article here explains how search syntaxes can be used within Hiveage.
Upcoming Work for Hiveage Search
The next major update we have planned for Hiveage is the completion suggester. This will make search in Hiveage quick and easy – when you start typing in the search box, we will suggest related terms to ease your searching. We are planning to use Elasticsearch’s lightning-fast completion suggester to achieve this.